T3Go is China’s first platform for smart travel based on the Internet of Vehicles. In this article, Trevor Zhang and Vino Yang from T3Go describe the evolution of their data lake architecture, built on cloud-native or open-source technologies including Alibaba OSS, Apache Hudi, and Alluxio. Today, their data lake stores petabytes of data, supporting hundreds of pipelines and tens of thousands of tasks daily. It is essential for business units at T3Go including Data Warehouse, Internet of Vehicles, Order Dispatching, Machine Learning, and self-service query analysis.
In this blog, you will see how we slashed data ingestion time by half using Hudi and Alluxio. Furthermore, data analysts using Presto, Hudi, and Alluxio saw the queries speed up by 10 times. We built our data lake based on data orchestration for multiple stages of our data pipeline, including ingestion and analytics.
I. T3Go data lake Overview
Prior to the data lake, different business units within T3Go managed their own data processing solutions, utilizing different storage systems, ETL tools, and data processing frameworks. Data for each became siloed from every other unit, significantly increasing cost and complexity. Due to the rapid business expansion of T3Go, this inefficiency became our engineering bottleneck.
We moved to a unified data lake solution based on Alibaba OSS, an object store similar to AWS S3, to provide a centralized location to store structured and unstructured data, following the design principles of Multi-cluster Shared-data Architecture; all the applications access OSS storage as the source of truth, as opposed to different data silos. This architecture allows us to store the data as-is, without having to first structure the data, and run different types of analytics to guide better decisions, building dashboards and visualizations from big data processing, real-time analytics, and machine learning.
II. Efficient Near Real-time Analytics Using Hudi
Our business in smart travel drives the need to process and analyze data in a near real-time manner. With a traditional data warehouse, we faced the following challenges:
- High overhead when updating due to long-tail latency
- High cost of order analysis due to the long window of a business session
- Reduced query accuracy due to late or ad-hoc updates
- Unreliability in data ingestion pipeline
- Data lost in the distributed data pipeline that cannot be reconciled
- High latency to access data storage
As a result, we adopted Apache Hudi on top of OSS to address these issues. The following diagram outlines the architecture:
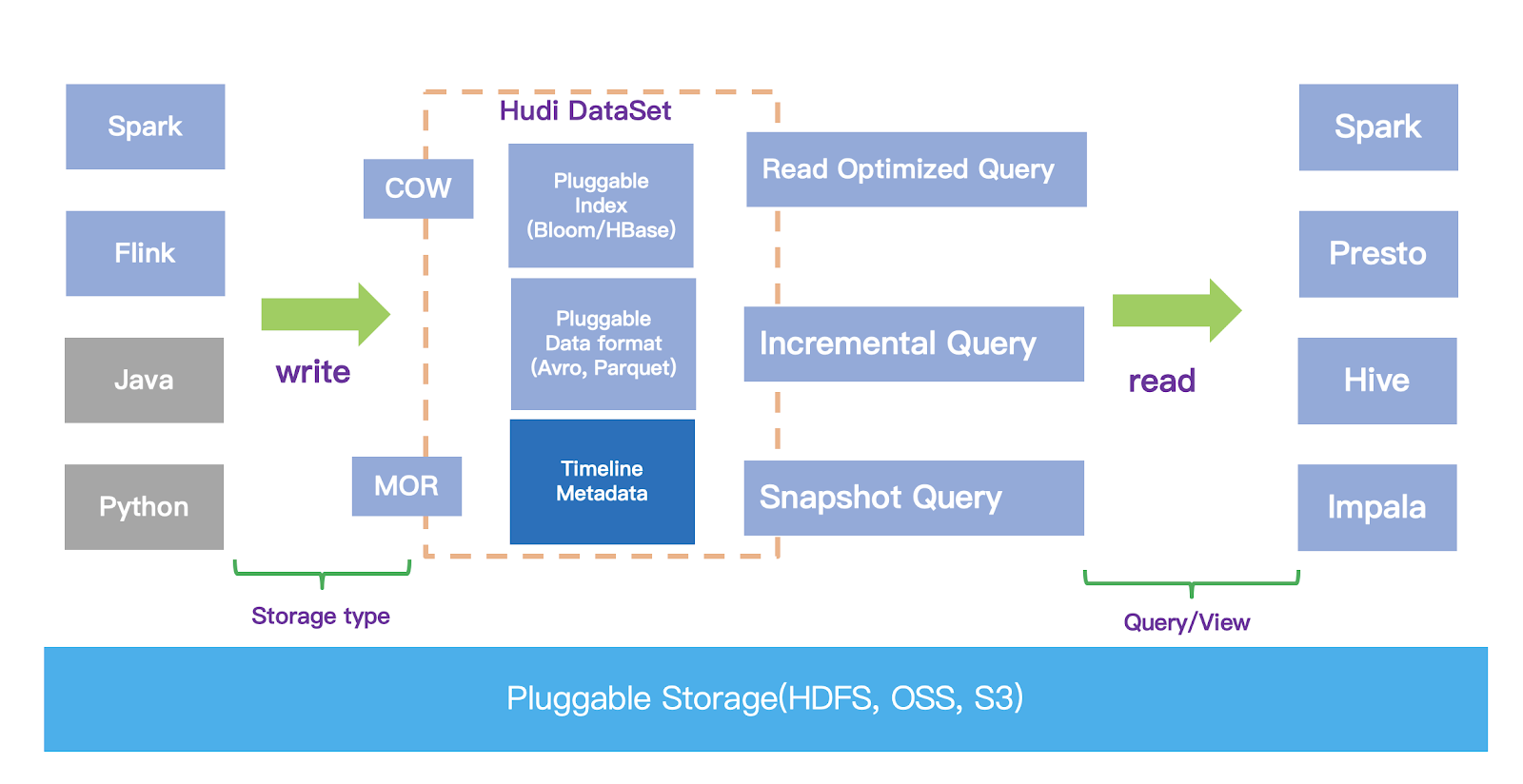
Enable Near real time data ingestion and analysis
With Hudi, our data lake supports multiple data sources including Kafka, MySQL binlog, GIS, and other business logs in near real time. As a result, more than 60% of the company’s data is stored in the data lake and this proportion continues to increase.
We are also able to speed up the data ingestion time down to a few minutes by introducing Apache Hudi into the data pipeline. Combined with big data interactive query and analysis framework such as Presto and SparkSQL, real-time data analysis and insights are achieved.
Enable Incremental processing pipeline
With the help of Hudi, it is possible to provide incremental changes to the downstream derived table when the upstream table updates frequently. Even with a large number of interdependent tables, we can quickly run partial data updates. This also effectively avoids updating the full partitions of cold tables in the traditional Hive data warehouse.
Accessing Data using Hudi as a unified format
Traditional data warehouses often deploy Hadoop to store data and provide batch analysis. Kafka is used separately to distribute Hadoop data to other data processing frameworks, resulting in duplicated data. Hudi helps effectively solve this problem; we always use Spark pipelines to insert new updates into the Hudi tables, then incrementally read the update of Hudi tables. In other words, Hudi tables are used as the unified storage format to access data.
III. Efficient Data Caching Using Alluxio
In the early version of our data lake without Alluxio, data received from Kafka in real time is processed by Spark and then written to OSS data lake using Hudi DeltaStreamer tasks. With this architecture, Spark often suffered high network latency when writing to OSS directly. Since all data is in OSS storage, OLAP queries on Hudi data may also be slow due to lack of data locality.
To address the latency issue, we deployed Alluxio as a data orchestration layer, co-located with computing engines such as Spark and Presto, and used Alluxio to accelerate read and write on the data lake as shown in the following diagram:
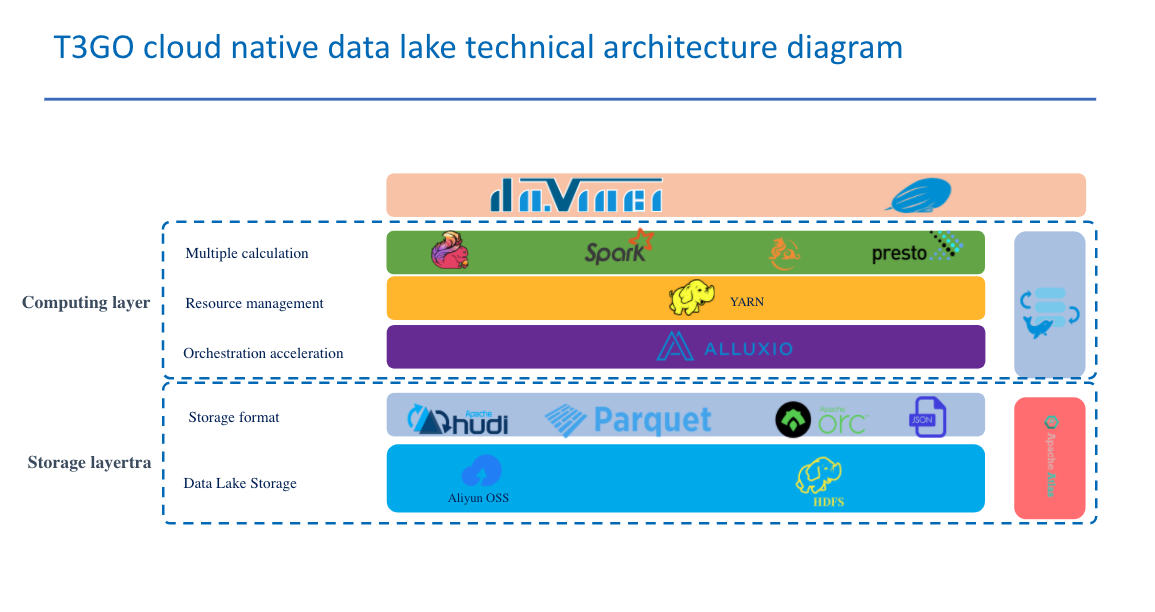
Data in formats such as Hudi, Parquet, ORC, and JSON are stored mostly on OSS, consisting of 95% of the data. Computing engines such as Flink, Spark, Kylin, and Presto are deployed in isolated clusters respectively. When each engine accesses OSS, Alluxio acts as a virtual distributed storage system to accelerate data, being co-located with each of the computing clusters.
Specifically, here are a few applications leveraging Alluxio in the T3Go data lake.
Data lake ingestion
We mount the corresponding OSS path to the Alluxio file system and set Hudi’s “target-base-path” parameter value to use the alluxio:// scheme in place of oss:// scheme. Spark pipelines with Hudi continuously ingest data to Alluxio. After data is written to Alluxio, it is asynchronously persisted from the Alluxio cache to the remote OSS every minute. These modifications allow Spark to write to a local Alluxio node instead of writing to remote OSS, significantly reducing the time for the data to be available in data lake after ingestion.
Data analysis on the lake
We use Presto as an ad-hoc query engine to analyze the Hudi tables in the lake, co-locating Alluxio workers on each Presto worker node. When Presto and Alluxio services are co-located and running, Alluxio caches the input data locally in the Presto worker which greatly benefits Presto for subsequent retrievals. On a cache hit, Presto can read from the local Alluxio worker storage at memory speed without any additional data transfer over the network.
Concurrent accesses across multiple storage systems
In order to ensure the accuracy of training samples, our machine learning team often synchronizes desensitized data in production to an offline machine learning environment. During synchronization, the data flows across multiple file systems, from production OSS to an offline HDFS followed by another offline Machine Learning HDFS.
This data migration process is not only inefficient but also error-prune for modelers because multiple different storages with varying configurations are involved. Alluxio helps in this specific scenario by mounting the destination storage systems under the same filesystem to be accessed by their corresponding logical paths in Alluxio namespace. By decoupling the physical storage, this allows applications with different APIs to access and transfer data seamlessly. This data access layout also improves performance.
Microbenchmark
Overall, we observed the following improvements with Alluxio:
- It supports a hierarchical and transparent caching mechanism
- It supports cache promote omode mode when reading
- It supports asynchronous writing mode
- It supports LRU recycling strategy
- It has pin and TTL features
After comparison and verification, we choose to use Spark SQL as the query engine. Our performance testing queries the Hudi table, comparing Alluxio + OSS together against OSS directly as well as HDFS.
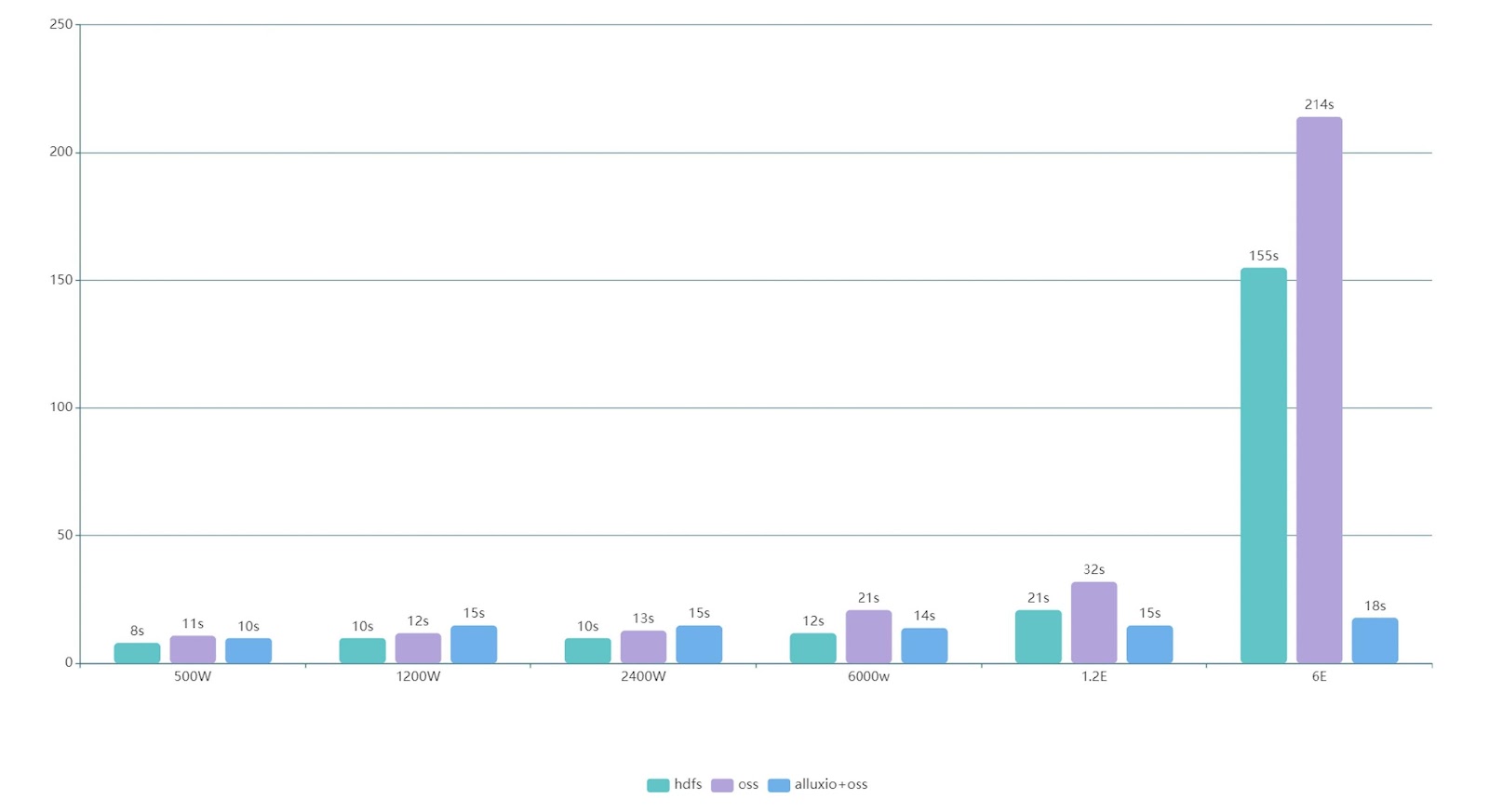
In the stress test shown above, after the data volume is greater than a certain magnitude (2400W), the query speed using Alluxio+OSS surpasses the HDFS query speed of the hybrid deployment. After the data volume is greater than 1E, the query speed starts to double. After reaching 6E data, it is up to 12 times higher than querying native OSS and 8 times higher than querying native HDFS. The improvement depends on the machine configuration.
Based on our performance benchmarking, we found that the performance can be improved by over 10 times with the help of Alluxio. Furthermore, the larger the data scale, the more prominent the performance improvement.
Iv. Next Step
As T3Go’s data lake ecosystem expands, we will continue facing the critical scenario of compute and storage segregation. With T3Go’s growing data processing needs, our team plans to deploy Alluxio on a larger scale to accelerate our data lake storage.
In addition to the deployment of Alluxio on the data lake computing engine, which currently is mainly SparkSQL, we plan to add a layer of Alluxio to the OLAP cluster using Apache Kylin and an ad_hoc cluster using Presto. The goal is to have Alluxio cover all computing scenarios, with Alluxio interconnected between each scene to improve the read and write efficiency of the data lake and the surrounding lake ecology.
V. Conclusion
As mentioned earlier, Hudi and Alluxio covers all scenarios of Hudi’s near real-time ingestion, near real-time analysis, incremental processing, and data distribution on DFS, among many others, and plays the role of a powerful accelerator on data ingestion and data analysis on the lake. With Hudi and Alluxio together, our R&D engineers shortened the time for data ingestion into the lake by up to a factor of 2. Data analysts using Presto, Hudi, and Alluxio in conjunction to query data on the lake saw their queries speed up by 10 times faster. Furthermore, the larger the data scale, the more prominent the performance improvement. Alluxio is an important part of T3Go’s plan to become a leading enterprise data lake in China. We look forward to seeing further integration with Alluxio in T3Go’s data lake ecosystem.