This blog is the first in a series introducing Alluxio as the data platform to unify data silos across heterogeneous environments. The next blog will include insights from PrestoDB committer Beinan Wang to uncover the value for analytics use cases, specifically with PrestoDB as the compute engine.
Alluxio started as a virtual distributed file system, a research project out of the AMPLab at U.C. Berkeley. Alluxio foresaw the need for agility when accessing large data stores separated from compute engines like Hadoop or Spark.
Fast forward several years and over a thousand committers later, and Alluxio has blossomed into the industry’s leading data orchestration platform for analytics and AI/ML. But as with any new type of technology, figuring out the best ways to use it depends on your data environment, computational workloads, issues, and goals.
So, after working with hundreds of organizations and fielding numerous inquiries, we thought it would be good to offer up a fresh take on the most popular use cases for Alluxio data orchestration.
Data Orchestration: Bringing Data Closer to Compute
The ability to quickly and easily access data and extract insights is increasingly important to any organization. With the explosion of data sources, the trends of cloud migration, and the fragmentation of technology stacks and vendors, there has been a huge demand for data infrastructure to achieve agility, cost-effectiveness, and desired performance.
To meet the demand, Alluxio provides a data abstraction layer that bridges computation frameworks and underlying storage systems. Alluxio is the only platform in the market today that brings together data locality with a distributed cache, API compatibility with popular data analytics and AI/ML frameworks, and a global namespace to federate data silos.
Alluxio is designed to help any framework access any data, from any storage at high performance regardless of your environment, which enables your organization to remain agile and competitive in adopting and experimenting with new and existing technologies.
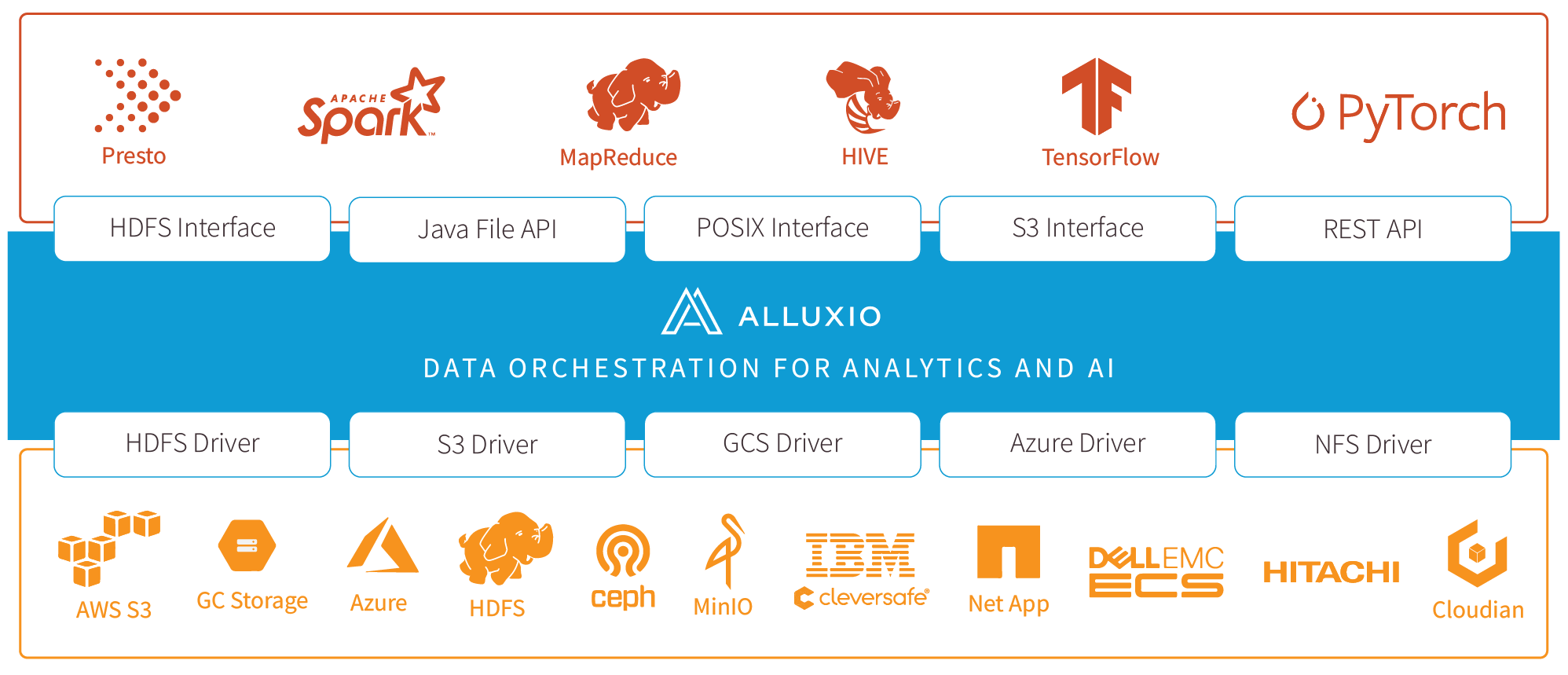
Thousands of companies leverage Alluxio at a large scale in production for modern data services. We have seen five common use cases to begin. With this overview, you will be able to tie this to your architecture and workloads and start using Alluxio. The first two use cases are single cloud or solely on-prem, while the following three use cases are for hybrid cloud environments.
- Cloud: achieve consistent SLAs and cost savings in a single cloud
- On-prem: speed-up analytics on on-prem object stores
- Hybrid cloud with compute in the cloud, data on-prem: burst compute to a public cloud and gradually migrate
- Hybrid cloud with data in the cloud and compute on-prem: gateway to utilize on-prem compute for data in the cloud
- Multi-datacenter: cross datacenter access without changing ingest pipeline across regions
Use Case 1: Achieve consistent SLAs and cost savings in a single cloud
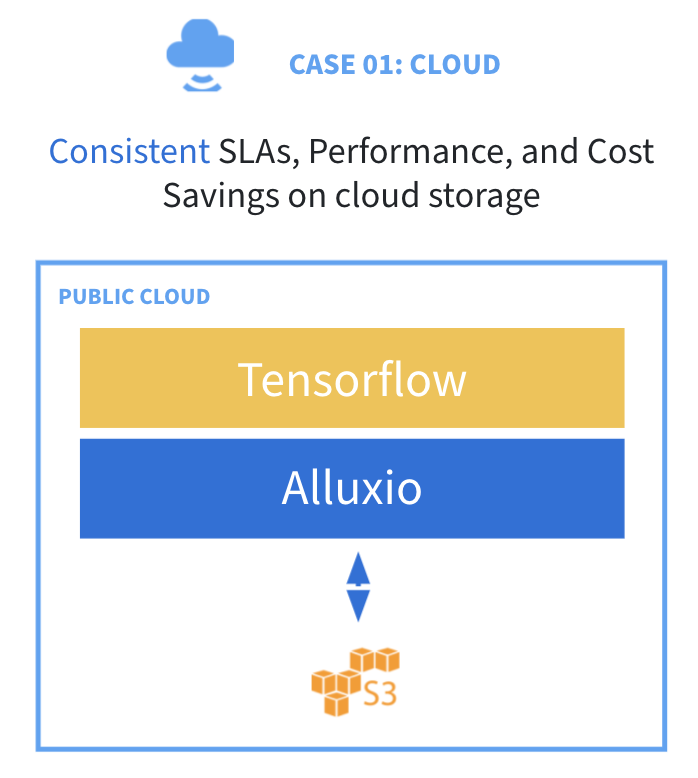
The first use case is to run data-intensive workloads in a single cloud. Although more organizations are choosing cloud object storage for cost-effectiveness, scalability and ease of use, they can hardly enjoy the same capabilities as a file system like HDFS.
For example, if you are running TensorFlow on top of AWS S3, one of the biggest challenges is the data access performance mismatch between the training frameworks on GPUs and cloud storage. Also, metadata operations are inefficient and expensive because of a pricing model based on the amount of access. Furthermore, when you are using ephemeral instances, the embedded caching solutions are not valid.
As a data orchestration platform, Alluxio addresses these challenges by providing intelligent caching and metadata management. When deploying Alluxio with the compute node, you can see significant performance gains while accessing data (2-7x for analytics engines, 1.7-2.3x for model training), and cost savings (cut storage access cost up to 50%). Alluxio not only handles the caching but also manages the corresponding metadata to avoid particular inefficient metadata operations and expensive metadata service costs. In addition, off-cluster caching for on-demand ephemeral workloads further makes consistent performance possible. Overall, with Alluxio as a data orchestration platform, you can achieve consistent SLAs and cost savings on cloud object stores. Alluxio can integrate with major cloud object stores including AWS S3, Azure Blob Store, Google Cloud Storage.
Electronic Arts, a leading company in the gaming industry, used Alluxio to achieve a high-performance platform on AWS to support real-time gaming services. Check out the case study here.
Use Case 2: Speed-up analytics on on-prem object stores

The second use case is to run data-driven applications on top of an object store deployed on-premise. Similarly, it is hard to achieve the desired performance for analytics and AI, and metadata operations lack performance. In addition, on-prem object storage does not provide as many native APIs for popular frameworks as cloud object stores do. As a result, applications have to use less optimal connectors to access on-prem object stores.
Alluxio, as a data orchestration platform, can improve the performance and handle the API translation, which will make onboarding to on-prem object storage seamless with a familiar security model. To access the underlying object storage, the applications only need to talk to Alluxio using conventional APIs and Alluxio handles the API translations behind the scenes. Thus, you can migrate workloads to the object store at your own pace without changing applications that affect the end-user experience. Furthermore, because Alluxio brings data closer to the compute frameworks, it will dramatically speed up Spark, Presto, Tensorflow, and other analytics frameworks on your object store with the flexibility of segregated storage. Alluxio supports any commercial object storage platform including Ceph, MINIO, Cleversafe, Dell EMC ECS, and more.
DBS, a top bank in Singapore, uses Alluxio to orchestrate data locally and makes numerous data applications accessible to the object storage. Check out the presentation here.
If you are working in a large organization, you are likely to face more complex data infrastructure in a hybrid cloud environment with disaggregated compute and storage over a network connection.
Use Case 3: Burst compute to a public cloud and gradually migrate
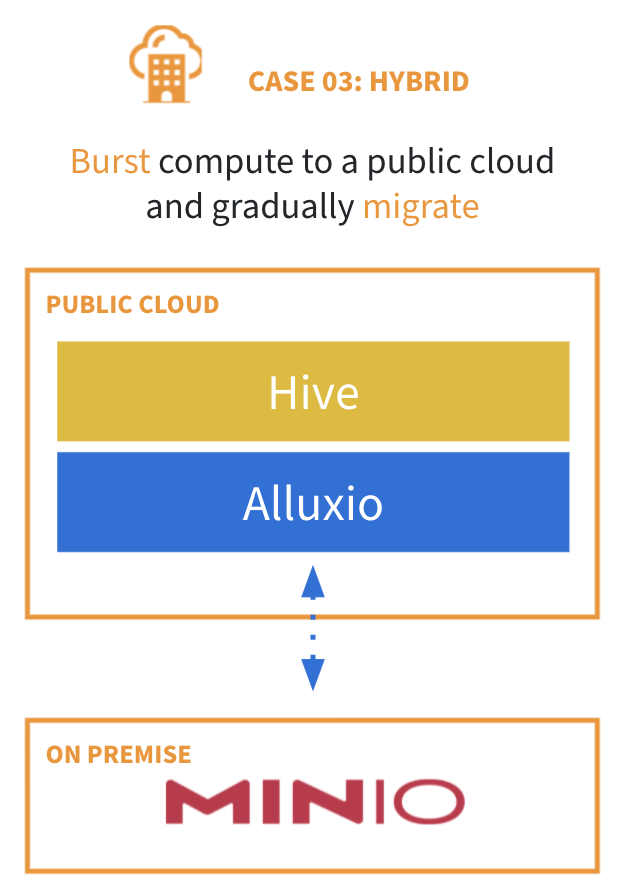
The third use case is to leverage the flexible compute resources on the public cloud so that you can migrate analytics or AI to the cloud and leave your data on-prem. This migration is not easy because of the limitation of network latency and bandwidth while running analytic workloads in the cloud with the data on-prem. The common solution is copying data into the cloud environment and maintaining the duplicate data on-prem (also called “lift and shift”). However, this solution is not only error-prone and also leads to issues in data consistency. Furthermore, some organizations may face compliance and data sovereignty requirements, preventing them from copying data into the cloud. The performance concern makes it difficult to progress with cloud migration.
Alluxio tackles these challenges by providing the “Zero-Copy” burst feature – this is one of the most powerful features that organizations benefit from Alluxio on their journey to the cloud. Zero-copy burst enables compute engines in the cloud to access data on-prem without a persistent data copy or synchronization. You can scale analytics workloads with no change in the end-user experience or the security model. In terms of performance, by bringing the data close to data analytics and machine learning applications on-demand, the performance is much better than directly accessing the remote data (an average of 3x improvement). Also, the on-prem data stores will have offloaded the computation and minimized the additional I/O overhead. In summary, Alluxio, as a data orchestration platform in the middle, handles data movement for high efficiency so that workloads can be migrated to the public cloud on-demand without moving data between computing environments first. Alluxio takes the charge of connecting to multiple stores so that you can gradually migrate the data using Alluxio to smooth your cloud migration journey.
Walmart leverages Alluxio for this use case. They used Presto in the cloud to handle more capacity for data analytics and offload previously on-prem Hive workloads, which wouldn’t be as seamless, high performing and cost-effective without Alluxio’s zero-copy burst. Check out Walmart’s presentation here.
Use Case 4: Hybrid cloud gateway to utilize on-prem compute for data in the cloud
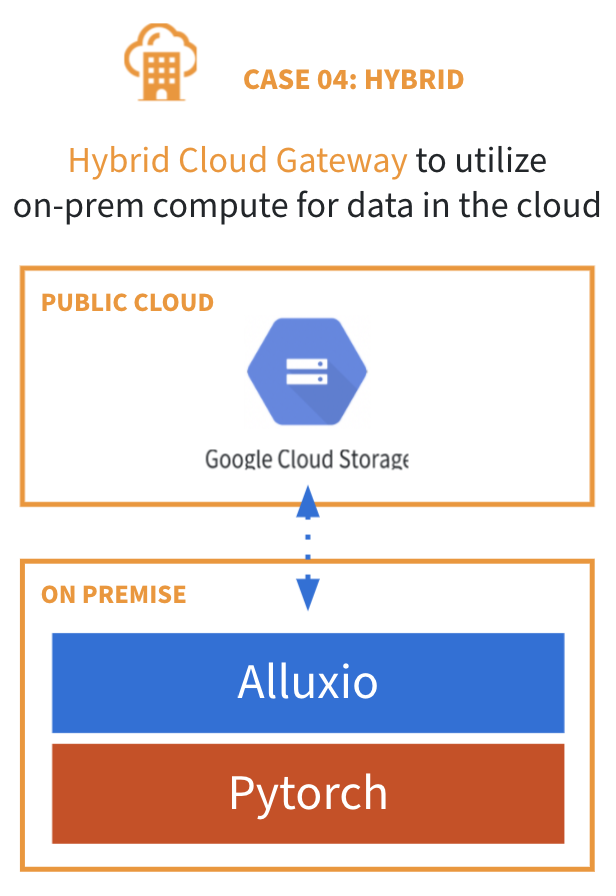
The fourth use case is to access cloud storage from a private data center, which is also a hybrid cloud architecture with decoupled object storage systems and compute nodes. Since the data is remote to the compute nodes, when running analytics directly on the object store, you will have to repeatedly pull the data from the storage nodes over the network, leading to inadequate performance and a high network egress cost.
Alluxio remedies these performance and cost issues by acting as a hybrid cloud storage gateway that utilizes on-prem compute for data in the cloud. When deployed with the compute on-prem, Alluxio manages the compute cluster’s storage and provides data locality to the applications. Alluxio also helps reduce a large amount of network egress costs by caching data, which avoids repeatedly fetching data directly from the cloud storage. Now you can keep the single source of truth in the cloud without sacrificing good performance or suffering from high egress costs by using Alluxio to fully leverage your existing compute-side resource deployments.
Comcast uses Alluxio to logically decouple compute and storage to enable rapid innovation in the storage and application layers. Check out the presentation here.
Use Case 5: Cross datacenter access without changing ingest pipeline across regions
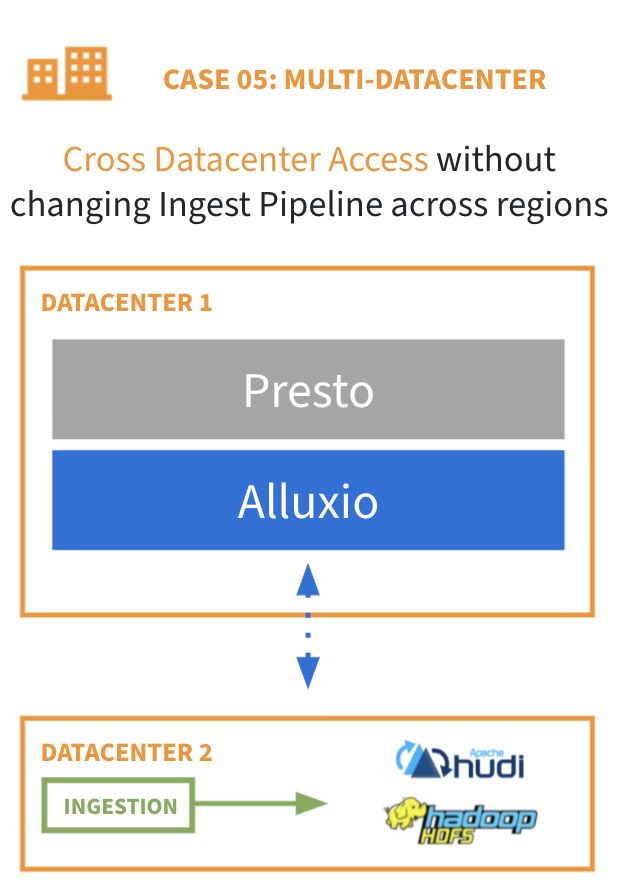
The fifth use case is in multiple datacenters where compute is in one data center and the primary data lake is in another data center. Many organizations maintain satellite compute clusters that are independent of their main data cluster for the purposes of performance, security, or resource isolation. These satellite clusters need to access data remotely from the main cluster, which would become overloaded, and dramatically impact the performance of existing workloads.
Alluxio’s data orchestration platform makes the multi-datacenter architecture more manageable. When deployed on the compute nodes in the satellite cluster and configured to connect to the main data cluster, Alluxio serves as one logical copy of data that provides the unified namespace as the main data cluster. Alluxio can accelerate the remote data read from the main data cluster without adding extra ETL steps. The intelligent data caching eliminates the performance bottlenecks, decreasing the overall load of the main data cluster. Thus, data platforms can be self-service across business units without changes to the applications.
At a leading SaaS company, the data application team used Alluxio to improve performance by ~3x and achieve self-service when adding satellite clusters to offload their central storage cluster.
Summary
With Alluxio, you can finally realize the technical and business benefits no matter if you are all on-prem, in the cloud, multi-cloud, or in a hybrid environment. Alluxio can help you achieve better agility, cost-effectiveness, and desired performance, which leads to faster time to insight to make better-informed decisions that provide a crucial competitive advantage. This is the reason why thousands of organizations choose Alluxio as the data orchestration platform to modernize their data infrastructure.
If you are interested in learning more about how Alluxio can help solve your challenges, contact us and request a demo today. You can also join our community slack channel to engage with our users or developers. And, of course, you can download a copy of the free Alluxio Community Edition or a trial of the full Alluxio Enterprise Edition to discover the benefits of data orchestration for your own use cases.