As the third largest e-commerce site in China, Vipshop processes large amounts of data collected daily to generate targeted advertisements for its consumers. In this article, Gang Deng from Vipshop describes how to meet SLAs by improving struggling Spark jobs on HDFS by up to 30x, and optimize hot data access with Alluxio to create a reliable and stable computation pipeline for e-commerce targeted advertising.
Overview
Targeted advertising is the key for many e-commerce companies to acquire new customers and increase their Gross Merchandise Volume (GMV). In modern advertising systems for e-commerce sites like VIP.com, analyzing data at a large scale is the key to efficient targeted advertising.
Every day at Vipshop, we run tens of thousands of queries to derive insights for targeted ads from a dozen of Hive tables stored in HDFS. Our platform is based on Hadoop clusters to provide persistent and scalable storage using HDFS and efficient and reliable computation using Hive MapReduce or Spark orchestrated by YARN. In particular, Yarn and HDFS are deployed together where each instance hosts both a HDFS DataNode process and a YARN NodeManager process.
In our pipeline, the input is historical data from the previous day. Typically, this daily data is available at 8 AM and the pipeline must complete within 12 hours due to the time-sensitivity of targeted ads. Among the various computation tasks, Spark accounts for 90% of the tasks and Hive takes up the remainder.
With Alluxio, we separate storage and compute by moving HDFS to an isolated cluster. Resources on the compute cluster are scaled independently of storage capacity, while using Alluxio to provide improved data locality by making additional copies for frequently accessed data.
Challenges
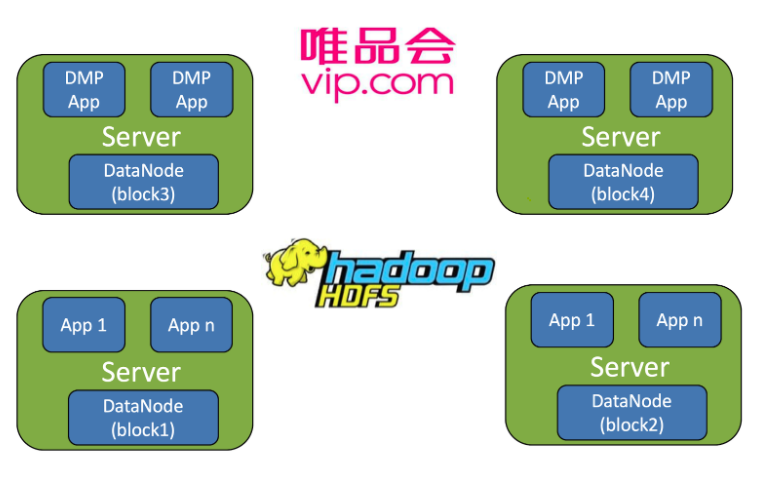
The major challenge when running jobs in the architecture shown in Figure 1 is inconsistent performance due to multiple reasons. Under ideal circumstances, it takes about 3 minutes to complete a single query. However, the time can vary as much as 10x, up to 30 minutes, as shown in Figure 2. This variation in performance makes it difficult to meet business requirements as operations are rarely completed by 8 PM.

After some preliminary investigation, we found that data locality was the main culprit. With a large number of nodes in the cluster, it is unlikely that the data needed by a computation process is served by the local storage process. Remote requests from other storage processes created bottlenecks on certain data nodes. All these factors contribute to a high variance when retrieving data from HDFS.
New solution with Alluxio
In looking for a solution, our goals to improve data locality throughout the cluster are:
- Achieve more local data reads with compute and storage processes co-located to avoid data transfer across the network. The particular scenario to avoid is when the same data is sent across the network multiple times.
- Reduce the impact of HDFS I/O on computation resources and vice versa. A desirable solution should have no resource contention between storage and computation.
- Serve as a model for other data pipelines. Although the solution should improve the targeted advertising data pipeline, the technology stack should be applicable for other applications and increase the stability and reliability of data pipelines throughout the business.
New Architecture
We chose to integrate Alluxio as a new solution; Figure 3 shows the new architecture after deploying Alluxio.

Deployment
In the architecture with Alluxio, the compute cluster is co-located with Alluxio and is separated from HDFS. This ensures compute jobs have no impact on HDFS I/O and vice versa. In order to keep the compute jobs compatible with the new architecture, we copied the existing Hive tables. The new tables point to the same underlying data in HDFS through Alluxio’s UFS to avoid any inconsistencies.
In addition to the recommended Spark configuration in Alluxio documentation, we also added following to the Spark configuration file:
spark.executor.extraJavaOptions
-Dalluxio.zookeeper.address=******:2181, ******:2181,******:2181 -Dalluxio.zookeeper.leader.path=/alluxio/leader
-Dalluxio.zookeeper.enabled=true
With this setting, the data passes into HDFS through Alluxio’s mounted UFS. When storing Hive table data to Alluxio, modify the Hive table metastore to point it to Alluxio by setting it to alluxio://zk@zkHost1:2181; zkHost2:2181; zkHost3:2181/path. With this configuration, the data in Alluxio can be accessed by Spark.

Figure 4 shows the compute results after deploying Alluxio.
SQL Test Results
Testing environment:
1.92TB SSD, 40 cores, 10000M/s network speed, 10 local machines
1). 100 SQLs, each SQL executed 5 times:

2). 500 SQLs, each SQL executed 1 time:

As shown, most queries with Alluxio improved by at least 10%, with an average improvement of around 30%.
Improvement with Alluxio
Our Hadoop cluster runs more than 700K ETL jobs. Network, CPU and disk are all saturated for a good part of the day. Workload fluctuation from numerous exploration jobs is especially difficult to predict and takes a heavy toll on the system as a whole. These exploration jobs cause significant sporadic delays for all ETL jobs.

To ensure SLAs for time sensitive applications are met, one essential mechanism we employ is to run these in an isolated environment. We achieve this architecture by surrounding the main Hadoop cluster with multiple satellite clusters, each homogeneously configured to use SSDs.
The challenge for this architecture is turnaround time. At first, it took us weeks to set up a special purpose satellite cluster with carefully planning required for the memory and SSD capacity. As usage of a satellite cluster evolved, applications needed larger storage capacity. Scaling up the cluster was very time consuming as we had to get an additional infrastructure team involved for provisioning new hardware.
With Alluxio, adopting an architecture with satellite clusters was much easier; either as a standalone spark cluster or a yarn cluster with node labeling. Expanding or shrinking a cluster can now be done within hours instead of days. The main storage centric cluster is now offloaded as we can cherry pick hot data to cache on a compute centric satellite cluster, and also exploit local HDD if needed.

By integrating Alluxio into our stack, we can reliably meet our daily data pipeline deadlines for generating targeted advertising. The newly adopted technology stack is applicable not only to our specific use case, but also empowering data analysis applications across our business. At the same time, we were able to considerably save on total computing resources utilized at the marginal cost of provisioning additional SSD space. The additional SSD capacity is used by Alluxio to maintain the working set of data local to the tasks accessing it. The number of copies local to compute is now dictated by the application’s access pattern instead of a fixed number of copies for all data, as with the previous architecture, regardless of the data being recently accessed or not.
Conclusion
At the moment, Vipshop is only using Alluxio to address the data locality reading problem with HDFS. Among the various other use cases of Alluxio deployed in other companies, many are also applicable to Vipshop, so we hope to continue to explore how to better utilize Alluxio to stabilize and accelerate our data access. We look forward to continuing our collaboration with the Alluxio team.