In the rapidly-evolving field of artificial intelligence (AI) and machine learning (ML), the efficient handling of large datasets during training is becoming more and more pivotal. Ray has emerged as a key player, enabling large-scale dataset training through effective data streaming. By breaking down large datasets into manageable chunks and dividing training jobs into smaller tasks, Ray circumvents the need for local storage of the entire dataset on each training machine. However, this innovative approach is not without its challenges.
Although Ray facilitates training with large datasets, data loading remains a significant bottleneck. The recurrent reloading of the entire dataset from remote storage for each epoch can severely hamper GPU utilization and escalate storage data transfer costs. This inefficiency calls for a more optimized approach to managing data during training.
Ray primarily uses memory for data storage, with its in-memory object store designed for large task data. However, this approach faces a bottleneck in data-intensive workloads, as large task data must be preloaded into Ray’s in-memory storage before execution. Given that the object store’s size often falls short of the training dataset size, it becomes unsuitable for caching data across multiple training epochs, highlighting a need for more scalable data management solutions in Ray’s framework.
One of Ray’s notable advantages is its ability to utilize GPUs for training while employing CPUs for data loading and preprocessing. This approach ensures the efficient use of GPU, CPU, and memory resources within the Ray cluster. However, the disk resources are underutilized and lack efficient management. This observation leads to a transformative idea: building a high-performance data access layer by intelligently managing the underutilized disk resources across machines to cache and access training datasets. By doing so, we can significantly boost overall training performance and reduce the frequency of accessing remote storage.
Alluxio: Accelerating Training With Smart Caching
Alluxio accelerates large-scale dataset training by smartly and efficiently leveraging unused disk capacity on GPU and adjacent CPU machines for distributed caching. This innovative approach significantly accelerates data loading performance, crucial for training on large-scale datasets, while concurrently reducing dependency and data transfer costs associated with remote storage.
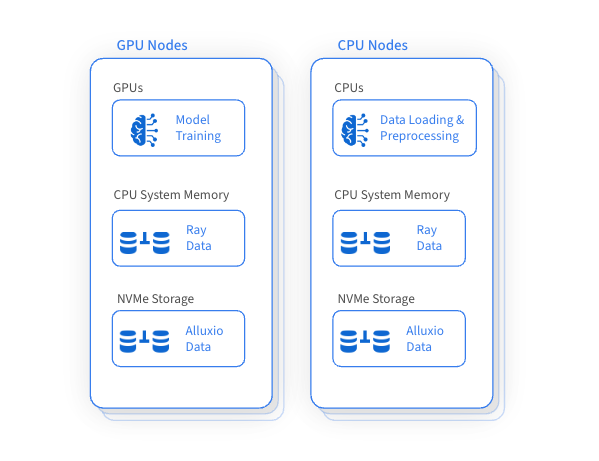
Integrating Alluxio brings a suite of benefits to Ray’s data management capabilities:
- Scalability
- Highly scalable data access and caching
- Enhanced Data Access Speed
- Leverage high performance disk for caching
- Optimized for high concurrent random reads for columnar format like Parquet
- Zero-copy
- Reliability and Availability
- No single point of failure
- Robust remote storage access during faults
- Elastic Resource Management
- Dynamically allocate and deallocate caching resources as per the demands of the workload
Ray and Alluxio Integration Internals
Ray efficiently orchestrates machine learning pipelines, integrating seamlessly with frameworks for data loading, preprocessing, and training. Alluxio serves as a high-performance data access layer, optimizing AI/ML training and inference workloads, especially when there’s a need for repeated access to data stored remotely.
Ray utilizes PyArrow to load and convert data formats into Arrow format, which will be further consumed by the next stages in the Ray pipeline. PyArrow delegates storage connection issues to the fsspec framework. Alluxio functions as an intermediary caching layer between Ray and underlying storage systems like S3, Azure blob storage, and Hugging Face.
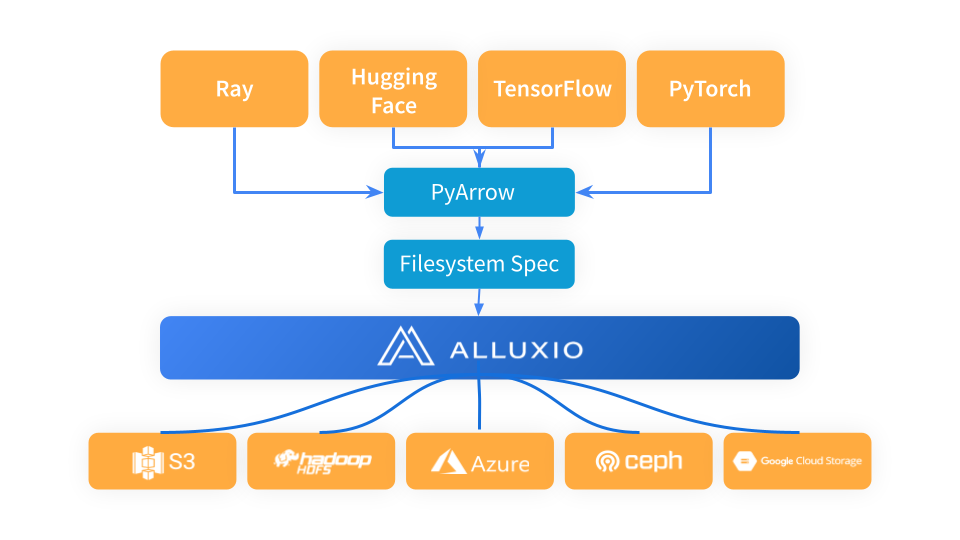
When using Alluxio as the caching layer between Ray and S3, simply import alluxiofs, init the Alluxio filesystem and change the ray filesystem to Alluxio.
# Import fsspec & alluxio fsspec implementationimport fsspec |
Benchmark & Results
We conducted experiments using a Ray Data nightly test to benchmark the data loading performance across training epochs between Alluxio and the same region S3. The benchmark results demonstrate that by integrating Alluxio with Ray, we can achieve considerable enhancements in storage costs and throughputs.

- Enhanced Data Access Performance: When the Ray object store is not under memory pressure, Alluxio’s throughput was observed to be 2x that of same-region S3.
- Increased Advantage Under Memory Pressure: Notably, when the Ray object store faced memory pressure, Alluxio’s performance advantage increased significantly, with its throughput being 5x higher than that of S3.
Conclusion
The strategic utilization of unused disk resources as distributed caching storage stands out as a crucial advancement for Ray workloads. This approach significantly improves data loading performance, proving particularly effective in scenarios where training or fine-tuning occurs with the same dataset across multiple epochs. Additionally, it becomes a critical asset when Ray faces memory pressure, offering a practical solution to optimize and streamline data management processes in these contexts. We are also working on a paper to discuss the integration of Alluxio into machine learning pipelines. Stay tuned.