In this article, Thai Bui describes how Bazaarvoice leverages Alluxio as a caching tier on top of AWS S3 to maximize performance and minimize operating costs on running Big Data analytics on AWS EC2. This article aims to provide the following takeaways:
- Common challenges in building an efficient big data analytics platform on AWS
- How to setup Hive metastore to leverage Alluxio as the storage tier for frequently accessed tables, backed by all tables on AWS S3 as the source of truth
- How to setup tiered storage within Alluxio based on ZFS and NVMe on EC2 instances to maximize the read performance
- Benchmark results of micro and real-world workloads
Our Big Data Workload and Platform on AWS
Bazaarvoice is a digital marketing company based in Austin, Texas. We are a software-as-a-service provider that allows retailers and brands to curate, manage, and understand user-generated content (UGC) such as reviews for their products. We provide services such as collecting and hosting reviews, programmatic management of UGC content, and deep analytics on consumer behavior.
Our globally distributed services analyze UGC content for over 1900 of the biggest internet retailers and brands. Data engineering at Bazaarvoice requires handling data at massive internet-scale. Take 2018 Thanksgiving weekend, for example, the combined 3-day holiday traffic generated 1.5 billion product page views and recorded $5.1 billion USD in online sales for our clients. Within a month, our services host and record web analytics events for over 900 million internet shoppers worldwide.
To keep up with the web traffic, we host our services via Amazon Web Service. The big data platform completely relies on the open source Hadoop ecosystem, utilizing tools such as:
- Apache Hive, Spark for ETLs
- Kafka, Storm for unbounded dataset processing
- Cassandra, ElasticSearch and HBase for durable datastore and long-term aggregations
The data generated by these various services is optimally formatted for analytics, such as Parquet or ORC, and is eventually stored in S3.
Why Alluxio
Using S3 to store our data enables us to increase our storage capacity effortlessly, but at the cost of incurring a performance bottleneck. Accessing sizable data from S3 is bottlenecked by the connection’s bandwidth. Since S3 is a managed service by AWS, it is not possible to write custom code to optimize to our specific environment, contrary to other open source technologies being utilized. One approach would be to provision more hardware to process data from S3 in parallel. But rather than spending more money on hardware, we decided to find a more ideal solution to solve this performance bottleneck.
We realized that not all data access needs to be fast because the workloads typically involved a subset of data. However this selective subset is constantly changing as newer data is added. This led us to come up with a tiered storage system to accelerate our data access, with the following goals:
- It should be nimble by expanding as our business grows without any data movement or introducing ETL jobs
- It should provide the same level of interoperability for most of our existing systems
- It should allow us to scale by utilizing better hardware when our budget allows for it.
Accelerate slow Hive read and write on AWS S3
With these criteria in mind, we decided to use Alluxio to accelerate our data access. As a key component in the tiered storage system, Alluxio was picked as it is highly configurable and relatively cheap to reconfigure operational-wise.
Architecture with Alluxio
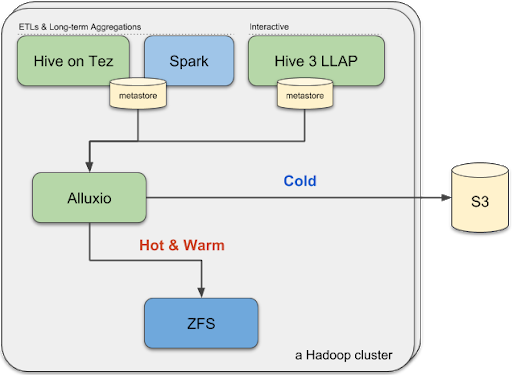
We integrated Alluxio with Hive Metastore as a basis for the tiered storage S3 acceleration layer. Clusters can be elastically provisioned with support for our tiered storage layer.
In each job cluster (Hive on Tez & Spark) or interactive cluster (Hive 3 on LLAP), a table could be altered to have more relevant data configured to use Alluxio, while having the rest of the data served by S3 directly.
Since the data is not cached in Alluxio unless it is accessed via a Hive or Spark task, there’s no data movement. Since updating a table configuration is extremely cheap, adapting this pattern of changing queries has allowed us to be very nimble.
For example, let us look at our page view dataset. A page view is an event recorded when an Internet user visits a page on our client’s website. The raw data is collected, aggregated hourly, and converted into Parquet format. This data is stored in S3 in a year, month, day, and hour hierarchical structure:
s3://some-bucket/
|- pageview/
|- 2019/
|- 02/
|- 14/
|- 01/
|- 02/
|- 03/
|- pageview_file1.parquet
|- pageview_file2.parquet
The data is registered to one of our clusters via Hive Metastore and available to be used in Hive or Spark for analytics, ETLs, and other various purposes. An internal system registers the data and updates the Hive Metastore directly for every new dataset that it detects.
# add partition from s3. equivalent to always referencing “cold” data
ALTER TABLE pageview
ADD PARTITION (year=2019, month=2, day=14, hour=3)
LOCATION ‘s3://<bucket>/pageview/2019/02/14/03’
Our system is also aware of the tiered storage configuration provided for each specific cluster and table.
For instance, in an interactive cluster where analysts are analyzing the last few weeks of trending data, the pageview table with partitions less than a month old is configured to read directly from Alluxio filesystem. An internal system reads this configuration to mount the S3 bucket to the cluster via Alluxio REST API, then it automatically takes care of promoting/demoting tables and partitions using the following Hive DDLs:
# promoting. repeating query will cache the data from cold->warm->hot
ALTER TABLE pageview
PARTITION (year=2019, month=2, day=14, hour=3)
SET LOCATION ‘alluxio://<address>/mnt/s3/pageview/2019/02/14/03’
# demoting. 1 month older data goes back to the “cold” tier.
# this protects our cache when people occasionally read older data
ALTER TABLE pageview
PARTITION (year=2019, month=1, day=14, hour=3)
SET LOCATION ‘s3://<bucket>/pageview/2019/01/14/03’
As more recent data arrives, older data is demoted, requiring the tiered storage configuration to be updated. This process happens asynchronously and continuously.
Micro and Real-world Benchmark Results
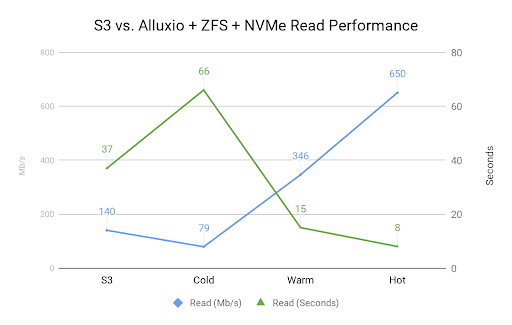
Our Alluxio + ZFS + NVMe SSD read micro benchmark is run on an i3.4xlarge AWS instance with up to 10 Gbit network, 128GB of RAM, and two 1.9TB NVMe SSDs. We mount a S3 bucket on Alluxio to perform 2 read tests. The first test copies 5GB of Parquet data using the AWS CLI into the instance’s ramdisk to measure only read performance.
# using AWS cli to copy recursively to RAM disk
$ time aws s3 cp --recursive s3://<bucket>/dir /mnt/ramdisk
The second test uses the Alluxio CLI to copy the same Parquet data to ramdisk. This time, we perform the test 3 times to get the cold, warm, and hot numbers as shown in the chart above.
# using AWS cli to copy recursively to RAM disk
$ time ./bin/alluxio fs copyToLocal /mnt/s3/dir /mnt/ramdisk
Alluxio v1.7 with ZFS and NVMe takes about 78% longer to perform a cold read when compared to S3 (66s vs. 37s). The successive warm and hot reads are 2.5 and 4.6 times faster than reading directly from S3.
However microbenchmarks don’t always tell the whole story, thus we will take a look at a few real-world queries executed by actual analysts at Bazaarvoice.
We rerun the same queries on our production interactive cluster to compare the tiered storage system against S3 by itself. The production cluster consists of 20 i3.4xlarge nodes running Hadoop 3, Hive 3.0 on Alluxio 1.7, and ZFS v0.7.12-1.
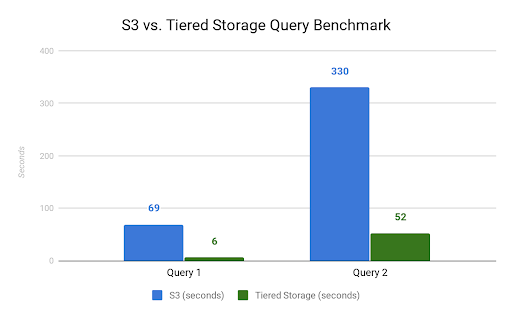
Query 1 is a single table deduplication query with 6 columns to group by. It processes 95M input records and 8G of Parquet data from a 200G dataset.
Query 2 is a more complex query, involving a join on 4 tables with aggregations across 5 columns. It processes 1.2B input records and 50G of Parquet data from several TB datasets.
The two queries simplified for readability and their query plans are shown below. Compared to running the queries directly on S3, the tiered storage system speeds up query 1 by 11x and query 2 by 6x.
# query 1 simplified
SELECT dt, col1, col2, col3, col4, col5
FROM table_1 n
WHERE lower(col6) = lower('<some_value>')
AND month = 1
AND year = 2019
AND (col7 IS NOT NULL OR col8 IS NOT NULL)
GROUP BY dt, col1, col2, col3, col4, col5
ORDER BY dt DESC
LIMIT 100;
Conclusion
Alluxio, ZFS, and the tiered storage architecture have helped us save a significant amount of time for analysts at Bazaarvoice. AWS S3 is easy to scale in capacity and by augmenting it with a tiered storage configuration that is nimble and cheap to adapt, we can focus on growing our business and scaling storage as needed.
Today at Bazaarvoice, the current production configuration can handle about 35TB of data in cache and half a petabyte of data on S3. In the future, we could simply add more nodes to grow the cache size or upgrade hardware for quicker localized access.