In this blog, we discuss the importance of data locality for efficient machine learning on the cloud. We examine the pros and cons of existing solutions and the tradeoff between reducing costs and maximizing performance through data locality. We then highlight the new-generation Alluxio design and implementation, detailing how it brings value to model training and deployment. Finally, we share lessons learned from benchmarks and real-world case studies.
1. Why Data Locality
Data locality refers to having compute jobs located close to the data they need to access. There are two major benefits to optimizing for data locality in cloud environments – improved performance and cost savings.
1.1 Performance Gain
Having data stored next to the compute allows for much faster access compared to retrieving that data from remote storage. This is especially impactful for data-intensive applications like machine learning and AI workloads. Locality reduces the time spent transferring data, accelerating the total time to completion for these jobs.
Specific performance gains include faster access to your data compared to remote storage and less time spent on data-intensive applications such as ML and AI. By keeping the needed data nearby, less time is wasted moving that data around and more time is spent on productive computation.
1.2 Cost Saving
In addition to faster job completion times, data locality also reduces costs in cloud environments.
Having compute close to data storage reduces the number of expensive API calls (LIST, GET operations) to external cloud storage services needed to repeatedly access or move data. Cloud costs are optimized through fewer operations to cloud storage for both data and metadata, as well as egress costs. With data locality, you will also achieve higher utilization of GPU hardware, leading to less total GPU rental time.
Overall, data locality leads to an overall increase in efficiency and a reduction in operational costs for cloud workloads.
2. Existing Solutions and Limitations
There are a few existing approaches that aim to improve data locality for machine learning workloads in the cloud. Each has its own advantages and limitations.
2.1 Read Data Directly From Remote Storage on the Fly
The simplest solution is to read data as needed directly from the remote cloud storage. This requires no locality setup and is easy to implement. However, the downside is that every training epoch needs to re-read the full dataset from the remote storage. Since multiple epochs are almost always needed for better model accuracy, this can take far more time than the actual model training computation.
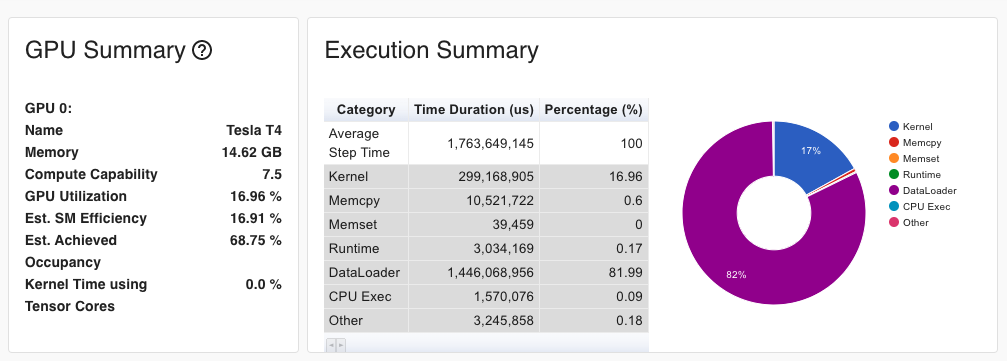
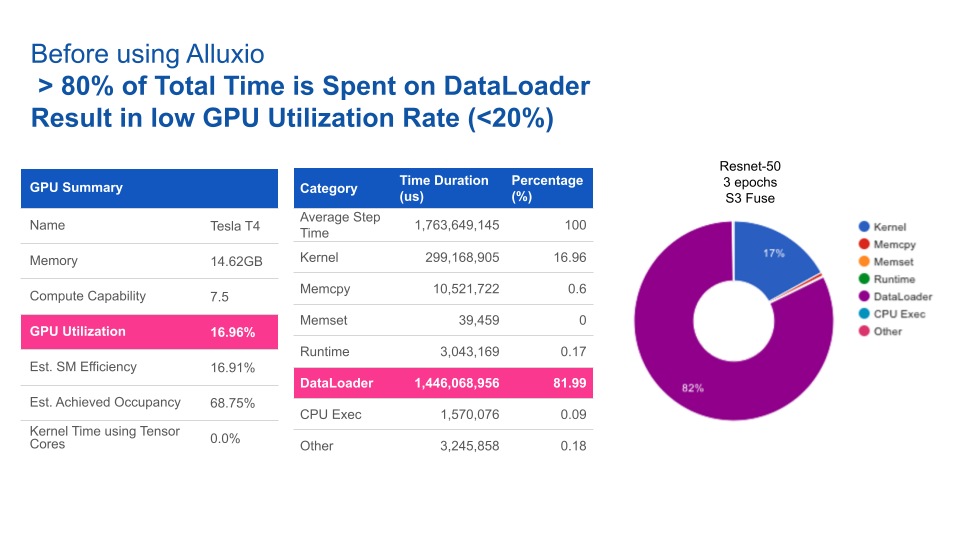
Through our test, we typically see that 80% of the time is spent on loading data from storage to the training cluster. See the DataLoader percentage in the below diagram.
2.2 Copy Data From Remote to Local Before Training
Another option is to manually copy the dataset from remote cloud storage into local disks/storage before kicking off training. This puts the data locally and confers all benefits of data locality in terms of performance and cost. The difficulties come from the management burden. Users have to manually delete the copied data after the job completes to free up limited local storage for the next job. This adds operational overhead.
2.3 Local Cache Layer for Data Reuse
Some storage systems like S3 provide built-in caching optimizations. There are also more advanced out-of-box solutions like Alluxio FUSE SDK that act as a local cache layer to buffer remote data. This cache can then be reused across jobs, keeping reused data local. The cache provider handles eviction and lifecycle management, removing manual oversight needs. However, the capacity is still limited by the local disk, restricting its ability to act as a cache for huge datasets.
2.4 Distributed Cache System
Distributed cache system can span many nodes, creating a shared cache layer that can store vastly larger volumes of hot data. In addition, it handles data management tasks like tiering and eviction automatically.
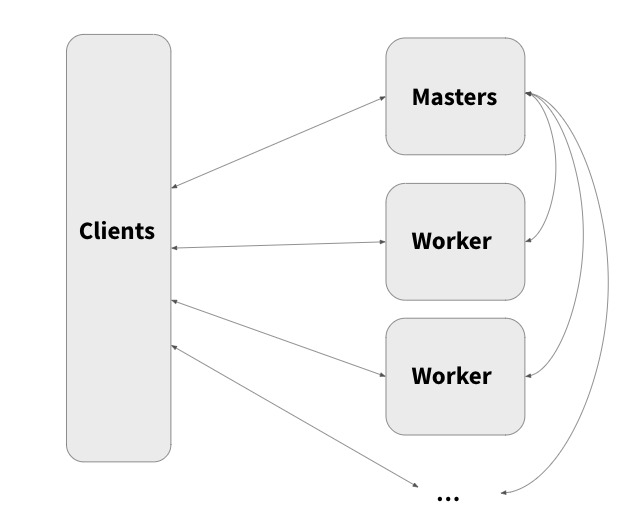
However, in legacy distributed caching solutions, there are still some limitations around master availability. The large number of small files also creates bottlenecks. Ongoing challenges remain around scalability, reliability, and meeting expanding data demands.
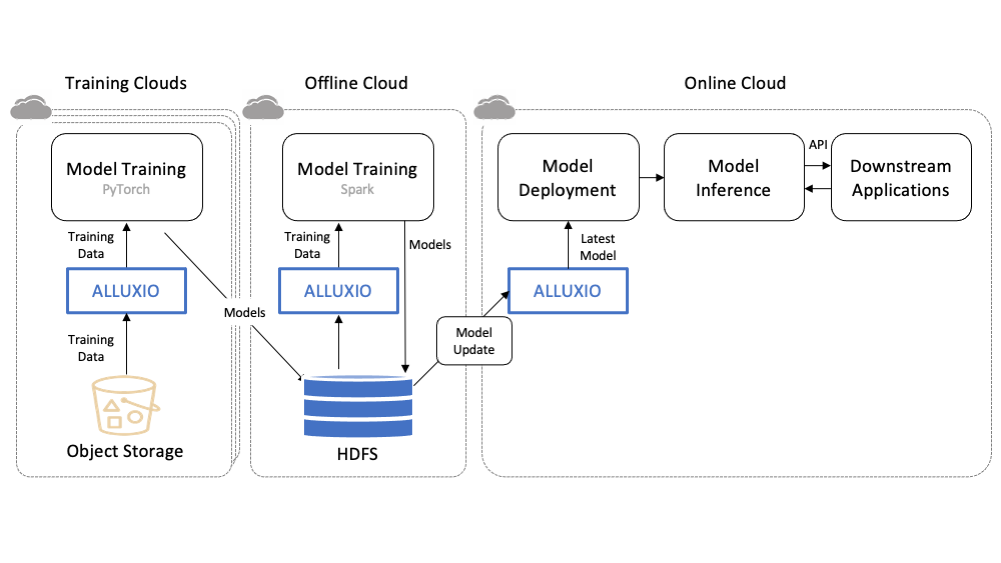
3. A New Design: Alluxio DORA Architecture
To overcome limitations around scalability, reliability, and performance in existing distributed caching solutions, a new design, Alluxio DORA (Decentralized Object Repository Architecture), is proposed, leveraging consistent hashing and soft affinity scheduling.
3.1 Consistent Hashing for Caching
The core idea is to use consistent hashing to determine data and metadata caching locations across worker nodes. This allows both cache data and cache lookups to be distributed across workers rather than centralized on single masters.
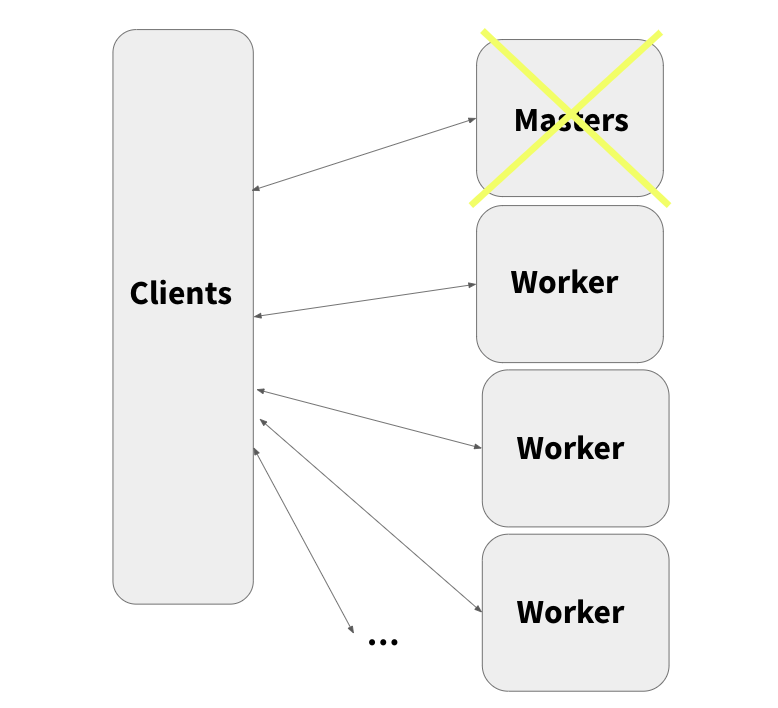
The benefits of this approach include:
- Worker nodes have abundant local storage space for caching
- No single point of failure risk
- No performance bottlenecks on master nodes
In addition, the consistent hashing algorithm handles rebalancing and redistribution automatically when nodes are added or removed.
3.2 Soft Affinity Caching Solution
Building on a consistent hashing foundation, a soft affinity caching algorithm is used to optimize data locality further. The steps of the algorithm are:
- Step 1: Configure the desired number of cache replicas for each data object
- Step 2: Use consistent hashing to determine the first-choice target node for placing each cache replica
- Step 3: Then re-run consistent hashing based on the first-choice node to calculate a second-choice alternative node
- Step 4: Repeat to assign multiple affinity-based caching locations for each replica
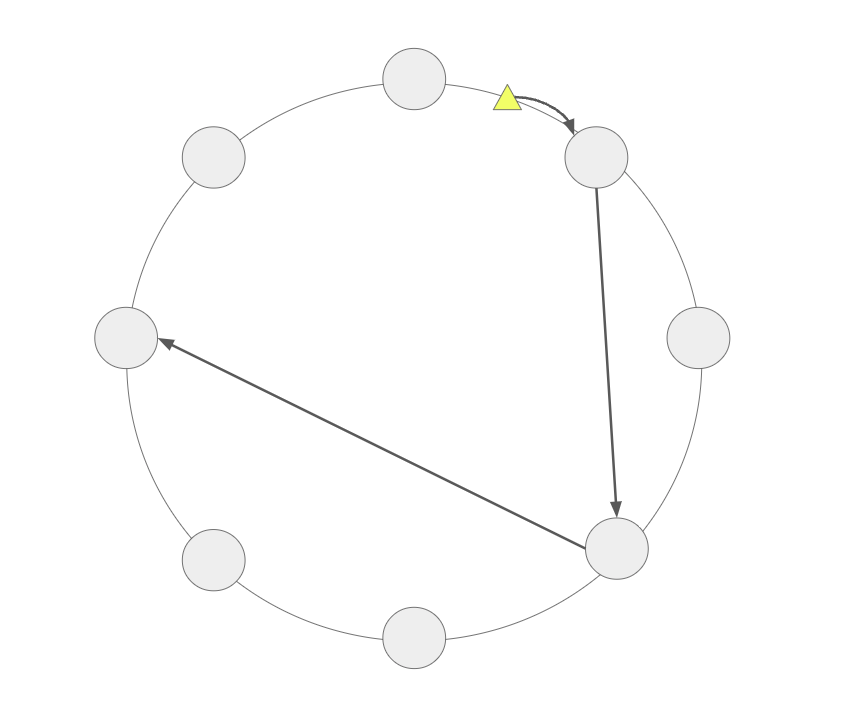
This creates graded affinity preferences for data caching targets. Combined with consistent hashing for decentralization, soft affinity caching allows optimization of data locality while maintaining scalability and reliability.
4. Implementation
The proposed distributed caching design has been implemented in Alluxio’s new Enterprise AI product.
4.1 Implementation
Alluxio’s new-generation architecture implements the soft-affinity scheduling algorithm for distributed data caching. Key implementation highlights:
We have also achieved high scalability – a single Alluxio worker can handle 30 to 50 million cached files. It is also designed for high availability, targeting 99.99% uptime with no single point of failure. In addition, a cloud-native Kubernetes operator handles tasks like deployment, scaling, and lifecycle management.
4.2 CSI & FUSE for Training
The new generation Alluxio integrates with Kubernetes through CSI and FUSE interfaces to enable direct access to cache tiers from training pods.
The FUSE implementation exposes remote cached data as a local folder, greatly simplifying mounting and usage. The CSI integration launches worker pods on-demand only when datasets are actually accessed. This increases efficiency.
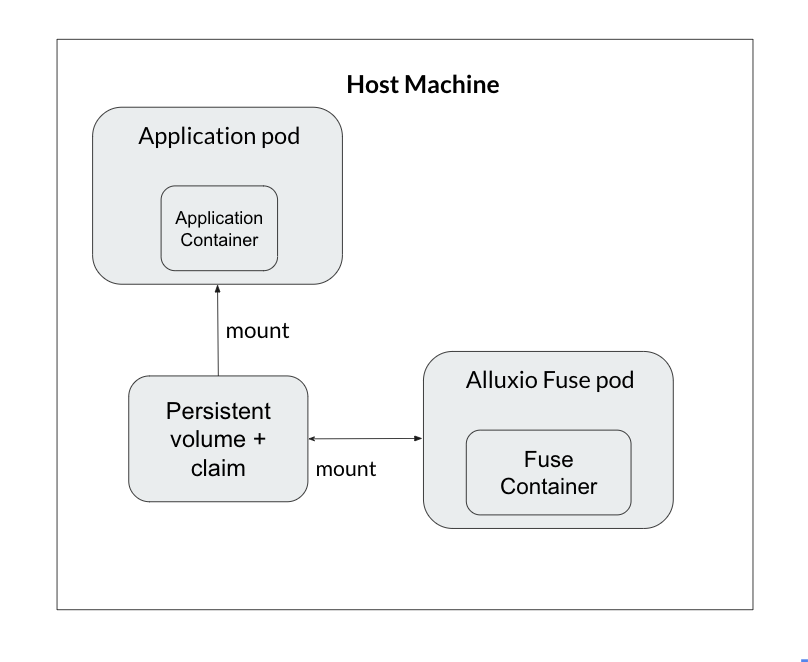
Together, these provide three tiers of caching – kernel, disk SSD, and Alluxio distributed cache – to optimize for data locality.
4.3 Performance Benchmark
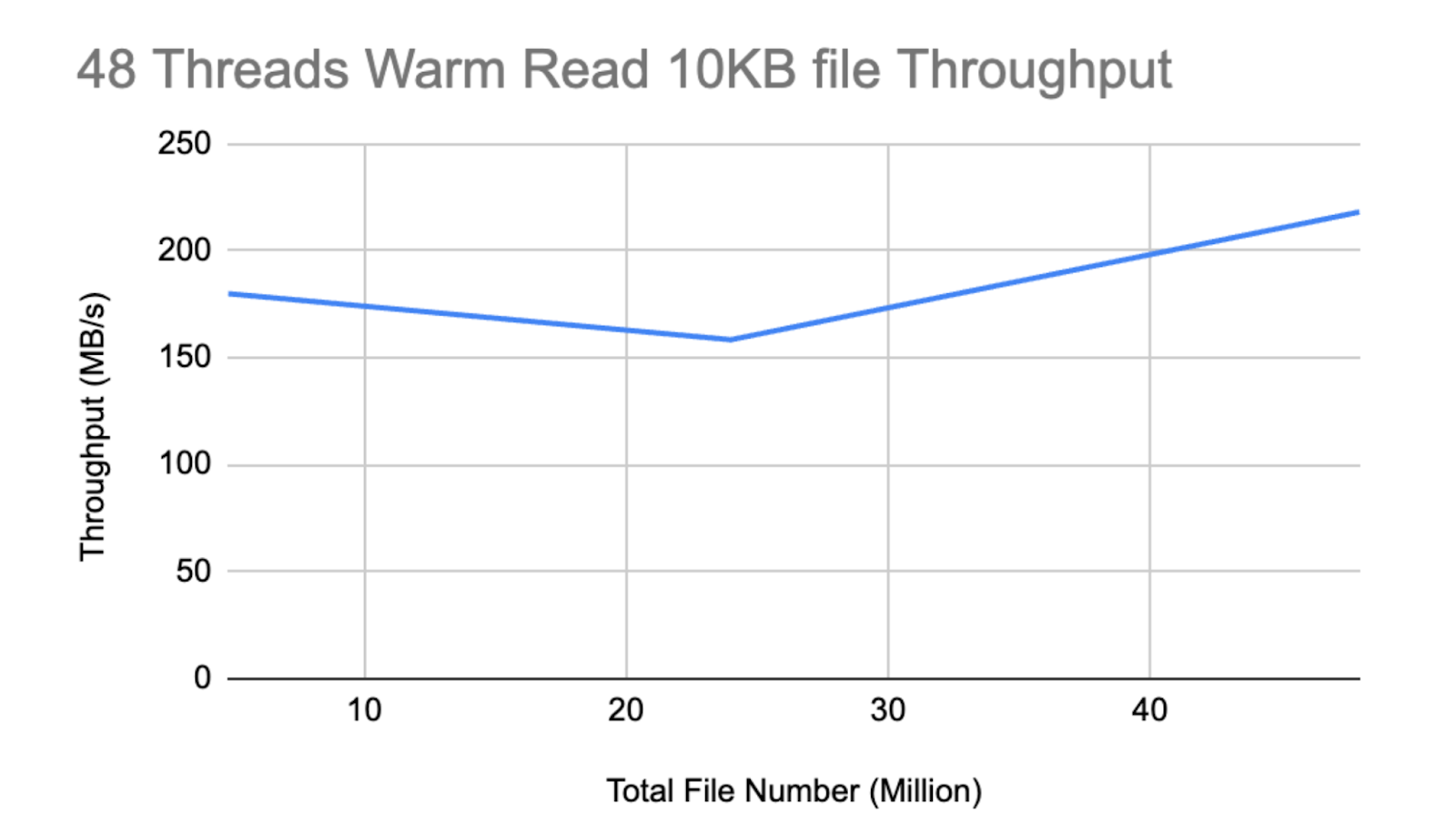
In the single worker performance benchmark test, we used three data points – 4.8 million files, 24 million files, and 48 million files. The worker was able to store and serve 48 million files without any significant performance downgrade.
In the data loading performance tests, we did both computer vision tests using a subset of imagenet and NLP tests using the yelp academic dataset. Test results show that Alluxio FUSE is 2~4x faster than S3FS-FUSE in terms of IOPS and throughput.


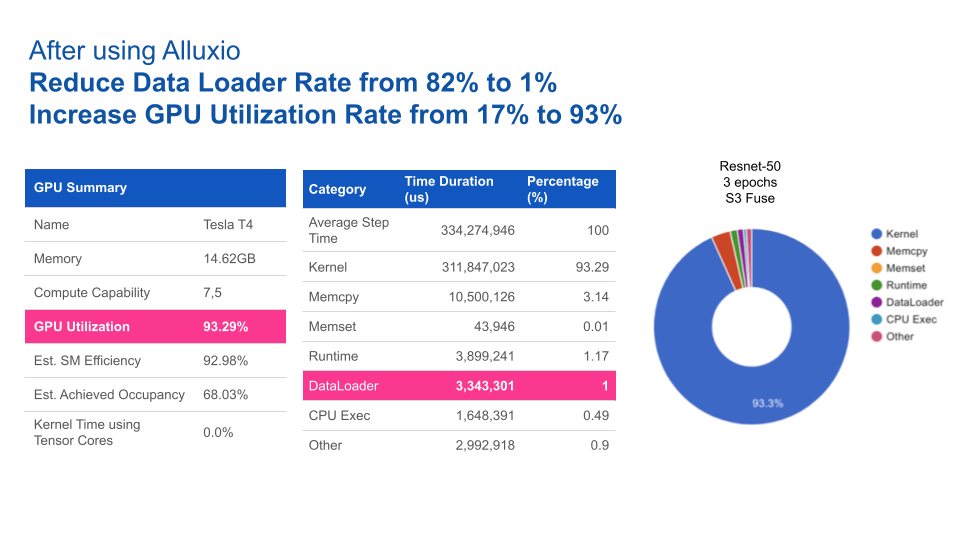
For CV training, with data loading time reduced, GPU utilization is increased from 17% to 93%.
5. Production Case Study: Zhihu
Zhihu, a top online Q&A platform, deploys Alluxio as a high-performance data access layer for LLM training and serving. Alluxio has accelerated model training by 2~3x, increased GPU utilization by 2x, and enabled model deployment every minute instead of hours or days. You can read the full story in this blog post: https://www.alluxio.io/blog/building-high-performance-data-access-layer-for-model-training-and-model-serving-for-llm/
6. Summary
To recap, here are the key takeaways from the blog:
- Data locality is critical for the performance and cost optimization of machine learning workloads in the cloud. Storing data near compute not only reduces the latency of data access but also saves cloud storage costs.
- Existing solutions, including direct remote access, copy data, and local cache layer, have their pros and cons, but all struggle to provide data locality at scale.
- The new solution, Alluxio DORA architecture, introduces a distributed caching architecture leveraging consistent hashing for decentralization and a soft affinity scheduling algorithm for optimized data placement. This maintains high availability while improving locality.
- Benchmarks and real-world production cases demonstrate Alluxio DORA’s ability to provide locality-like performance for AI to handle huge datasets with minimal costs.
To learn more about Alluxio, join 11k+ members in the Alluxio community slack channel to ask any questions and provide feedback.