TensorFlow is an open source machine learning platform used to build applications like deep neural networks. It consists of an ecosystem of tools, libraries, and community resources for machine learning, artificial intelligence and data science applications. S3 is an object storage service that was created originally by Amazon. It has a rich set of API’s that abstract the underlying object data store, allowing access from virtually anywhere over the network
Training a neural network using TensorFlow is a complex process. For training, large amounts of samples need to be ingested, so as to iteratively adjust the weights, and minimize a loss function that represents the error of a network. For example, to do pattern recognition using a neural network, input data signals are weighted, summed and fed into a decision making activation function (in this case a sigmoid function) to produce the output decision.
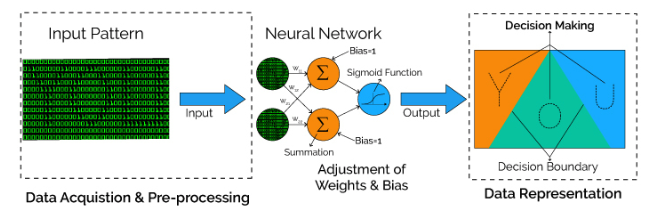
This process typically involves heavy I/O, and computationally intensive matrix operations that are spread across CPUs, GPUs and TPUs. However, data must be read from a backing store, and stores like S3 are commonly used along with TensorFlow.
So, what are some of the challenges using TensorFlow with S3, and how can you overcome these challenges?
Problems
In a distributed deep-learning application, the performance of the training library is dependent on the performance of the underlying storage sub-system and checkpointing process.
For a distributed training app, a typical setup looks like this –
- Input data is stored in a distributed store like S3.
- Data is shared between different workers, so that every worker can act on a unique subset of data.
- Results (including checkpoints) are written back into S3.
At the start of training, a considerable high number of relatively small files need to be read quickly and pre-processed on CPUs to be staged for the multi-layer’d training. During training, checkpointing (writes to capture intermediate state) is done periodically by the library so that TensorFlow can quickly backtrack and restart from an earlier checkpoint when needed.
In order to both share and save certain types of state produced by TensorFlow, the framework assumes the existence of a reliable, shared filesystem. However even though S3 might appear to be a perfect filesystem, underneath the covers, it is not a classic POSIX filesystem, and the differences are quite significant.
Here are a few commonly seen challenges of using TensorFlow with S3 –
- Reading and writing data can be significantly slower than working with a normal filesystem. S3 is not a POSIX filesystem, and libraries like TensorFlow typically have a layer of translation to S3 like this, which can add additional overhead.
- Changes made in a typical filesystem is generally immediately visible, but in the case of objects stores like S3, changes are eventually consistent. The output of the TensorFlow computation may not be immediately visible.
- Network delays in S3 API access will cause an additional overhead, while models are executed on real-time data. File operations such as rename are also quite expensive and would require multiple slow HTTP REST calls (copy to destination, and delete source) to complete.
- Egress costs can become explosive using S3 since there are a large number of relatively small objects to transfer.
How Alluxio Helps
The Alluxio POSIX API enables data engineers to access any distributed file system or cloud storage as if accessing a local file system with an added performance improvement. This avoids the performance penalty of connectors with overlaying layers. Alluxio improves performance by preloading the dataset or caching on demand and co locating dataset locally with computing clusters. One can deploy a layer of data orchestration like Alluxio to serve the data to TensorFlow to improve the end-to-end model development efficiency. For example, Alluxio can be deployed colocated with the training cluster, exposing the training data through Alluxio POSIX or HDFS compatible interfaces, backed by the mounted remote storage like S3. The training data can be pre-loaded to Alluxio from the remote storage or cached on demand. See documentation for more details.