Increasingly S3 is being used as a data store for analytical and machine learning workloads. This means that it is very easy to generate a massive amount of get operations and request data from S3. For example: a couple of commands can launch a 1000 node cluster of AWS EMR service with the Spark or Presto service running on each node. This means that every split / executor can request data from S3.
While S3 500 or 503 errors are not extremely common, every now and then you may hit these errors.
The error code “500 Internal Server Error” means that S3 is unable to service the request at the moment. This could be for a few reasons, S3 service itself has an internal error. or it could mean that the rate of data access is too high.
The error code 503 “503 Slow Down” or “503 Service Unavailable” indicates that Amazon S3 is unable to handle the request because you need to slow down requests or are exceeding requests to the S3 bucket.
Solution
In case of the 500 error, the best option is to retry. But since this error is unpredictable, maintaining a consistent SLA or a consistent user experience is difficult.
In case of the 503 error, usually an exponential backoff is recommended. Exponential backoff is an approach that multiplicatively decreases the rate at which you request objects from S3, in order to gradually find an acceptable rate.
But in both these cases, simply retrying may not be an option, because the application is essentially blocked and waiting.
Another approach is to abstract object stores like S3 using a data orchestration layer like Alluxio. Technologies like Alluxio orchestrates data from S3 closer to the compute frameworks. What this does is mounts data from S3 into Alluxio on the same instance as where the compute framework is running. Data is read directly from Alluxio as a cache and the impact of any AWS 5xx error on read when data is already in Alluxio can be completely eliminated. Try it free today.
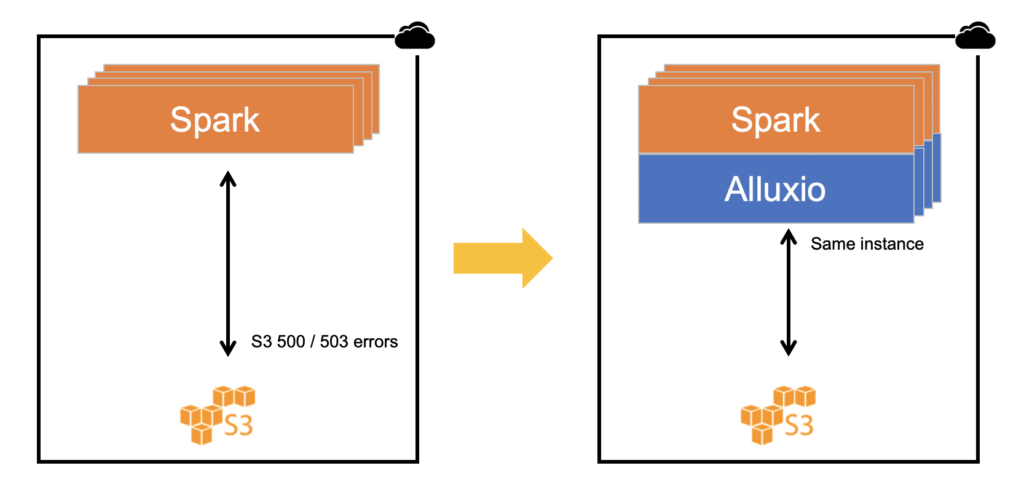
In addition, AWS errors can be avoided on write / put operations as well. Alluxio includes an asynchronous write option. This means that any writes to S3 are completely abstracted. The application / client control is return and it does not wait for the data to be written to S3. For additional durability, data can be replicated within the Alluxio cluster using adaptive replication as well.
You can get started with EMR and Alluxio here: https://www.alluxio.io/products/aws/aws-emr-tutorial-ami/
You can find the full S3 Error Code List here: https://docs.aws.amazon.com/AmazonS3/latest/API/ErrorResponses.html#ErrorCodeList